【阅读时间】7 - 10 min | 4300字
【阅读内容】结合应用场景,总结有关二叉树遍历的所有算法和对应Leetcode题目编号。基于Python代码,给出完整逻辑链。希望给读者一个线头,让你永远忘不了这几个遍历算法
遍历算法总览
遍历的含义就是把树的所有节点(Node)按照某种顺序访问一遍。包括前序,中序,后续,广度优先(队列),深度优先(栈)5中遍历方法
| 遍历方法 | 顺序 | 示意图 | 应用 |
|---|---|---|---|
| 前序 | 根 ➜ 左 ➜ 右 | 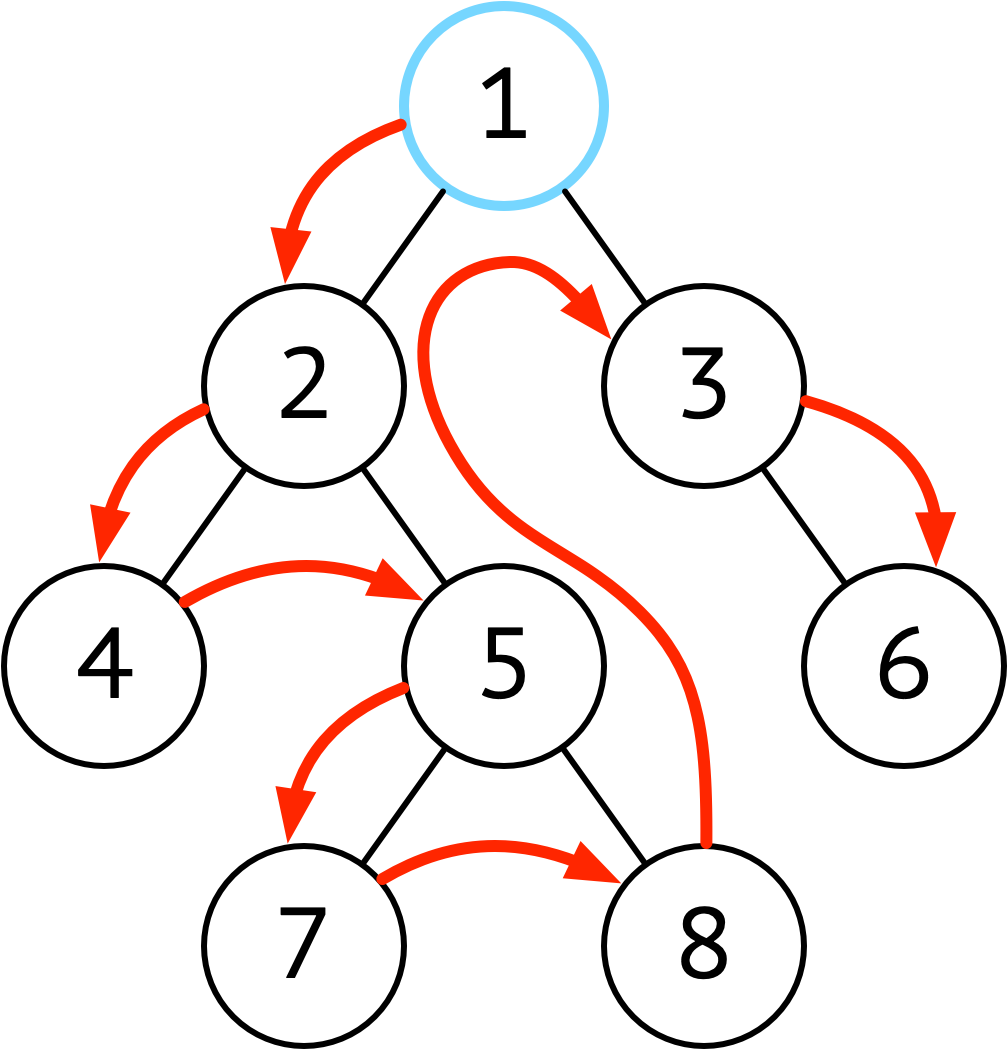 |
想在节点上直接执行操作(或输出结果)使用先序 |
| 中序 | 左 ➜ 根 ➜ 右 | 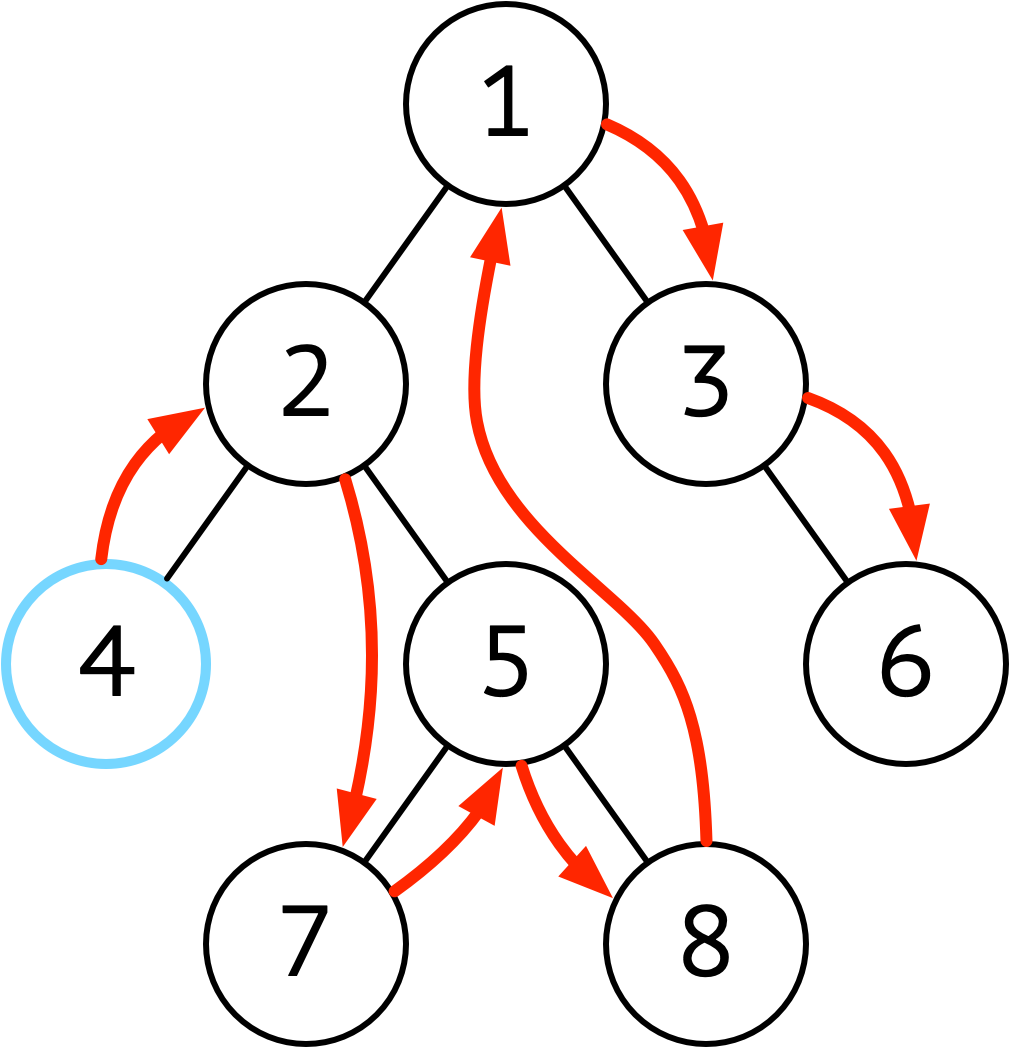 |
在二分搜索树中,中序遍历的顺序符合从小到大(或从大到小)顺序的 要输出排序好的结果使用中序 |
| 后序 | 左 ➜ 右 ➜ 根 | 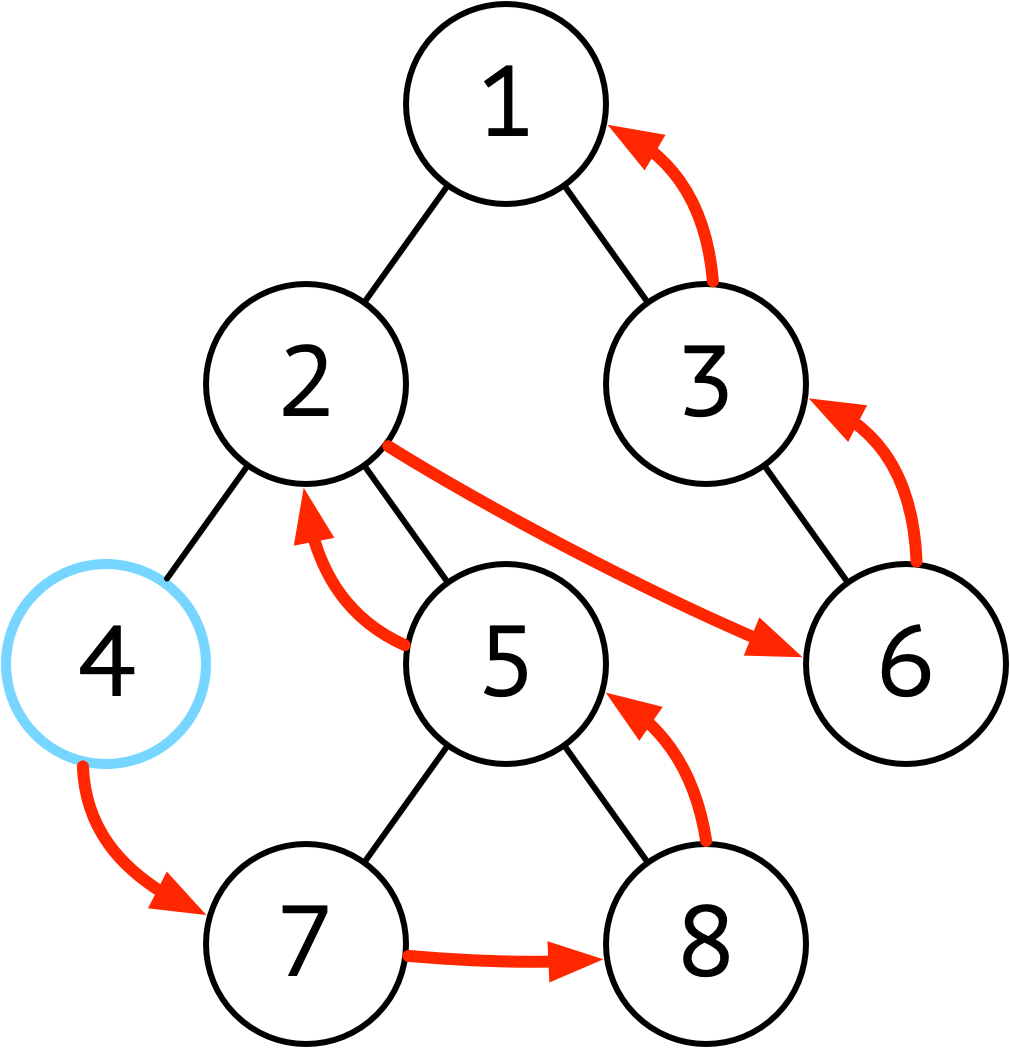 |
后续遍历的特点是在执行操作时,肯定已经遍历过该节点的左右子节点 适用于进行破坏性操作 比如删除所有节点,比如判断树中是否存在相同子树 |
| 广度优先 | 层序,横向访问 | 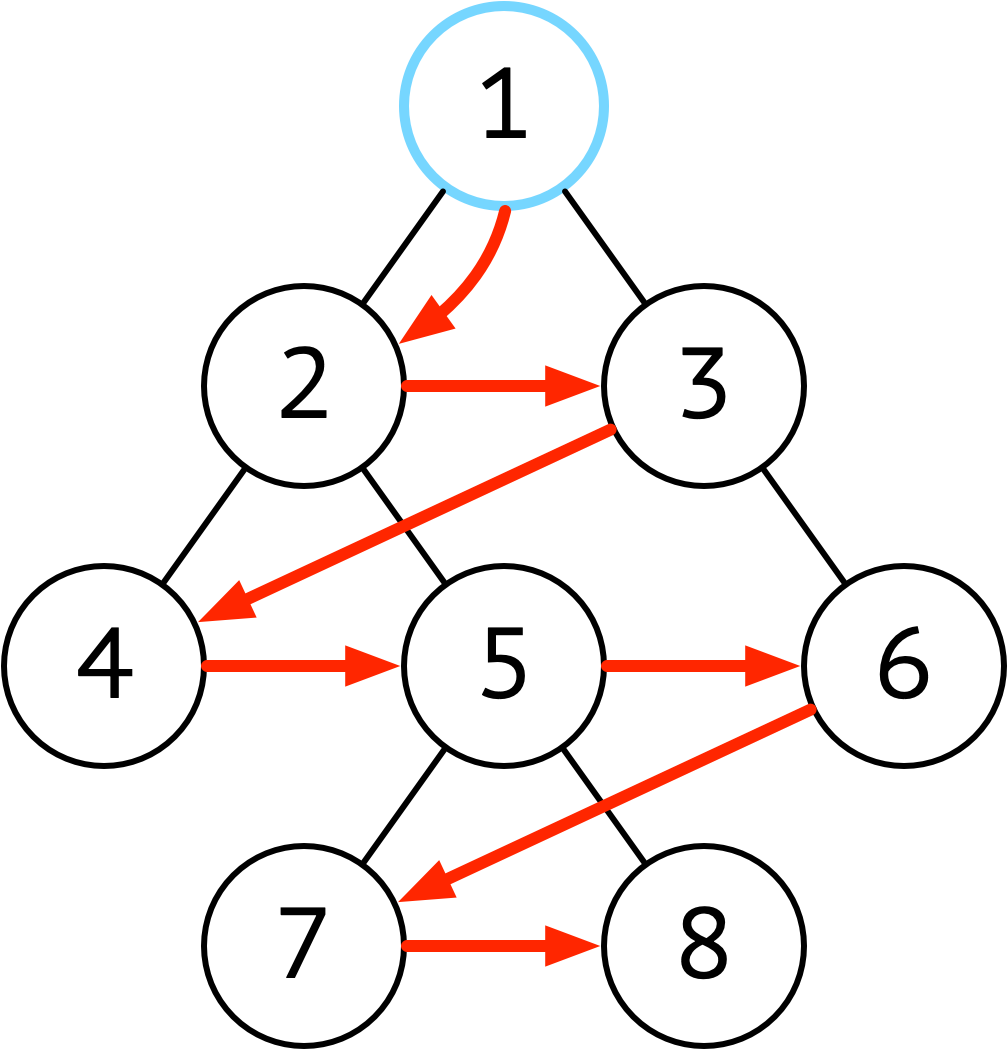 |
当树的高度非常高(非常瘦) 使用广度优先剑节省空间 |
| 深度优先 | 纵向,探底到叶子节点 |  |
当每个节点的子节点非常多(非常胖),使用深度优先遍历节省空间 (访问顺序和入栈顺序相关,想当于先序遍历) |
关于应用部分,选择遍历方法的基本的原则:更快的访问到你想访问的节点。先序会先访问根节点,后序会先访问叶子节点
需要说明的是,递归是一种拆分思维的具体问题类别的思维方法,其核心的思维我觉得和动态规划非常类似,都是假设子节点搞定了我现在应该干什么这个问题
先确定Python语言下的TreeNode定义
1 | class TreeNode: |
需要输出遍历结果时直接输出保存val的数组即可
关于递归算法的解释,博主打算写一份【直观算法】汉诺塔问题最全解答,过后可能会更新,是一篇小品文,比较短,这篇文章只是希望让所有阅读的人能一次就直观的搞明白汉诺塔的算法是怎么做的,永远记住它,也搞懂递归算法
三种遍历方法,都有一个特点,无论是先序根 ➜ 左 ➜ 右,中序左 ➜ 根 ➜ 右,后序左 ➜ 右 ➜ 根,所谓的访问顺序,根是最重要,根才代表了访问这个动作(在我们的代码中,就是把节点中的值加入到输出数组中),⭐️而根在的位置决定了是否可以访问的条件
比如对于中序来说,根在左的后面,意味着,只要当前操作的节点有左节点,就不能输出根里面的值
对于后序来说,有了这个直观理解,对理解三者的迭代算法有帮助
先序遍历
在线刷题:Leetcode 44. Binary Tree Preorder Traversal
递归算法
所谓递归(Recursive),即把函数本身看成一个已经有解的子问题
定义函数preorderTraversal(self, node)返回以node为答案的先序遍历结果的数组,假设它的两个孩子node.left和node.right已经搞定了,即可以返回答案的输出数组。那么思考最终的输出数组是什么样的,很明显要满足根 ➜ 左 ➜ 右的规则,应该返回[node.val] + preorderTraversal(self, node.left) + preorderTraversal(self, node.right)(函数返回的就是一个数组,只需要把它们拼接起来即可)
之后再完善防御性编程的基本步骤(保证函数输入有效),按照这个思路就可以写出先序遍历的递归代码。Python代码的特点是可读性比较强,这样一行代码简洁明了,能简洁的表达上面的逻辑链推理过程
1 | class Solution: |
当然,如果不使用Python,在语法上无法写的这么简短。常见的标准写法是使用helper()函数,具体实现见下
1 | def preorderTraversal1(self, root): |
迭代算法
同理,递归算法使用系统栈,不好控制,性能问题比较严重,需要进一步了解不用递归如何实现。为了维护固定的访问顺序,使用栈数据结构的先入后出特性
先处理根节点,根据访问顺序根 ➜ 左 ➜ 右,先入栈的后访问,为了保持访问顺序(先入后出),⭐️先把右孩子入栈,再入栈左孩子(此处需要注意,出栈才是访问顺序)
1 | class Solution: |
中序遍历
在线刷题:94. Binary Tree Inorder Traversal
递归算法
同理于前序遍历,一模一样的处理方法,考虑访问顺序为左 ➜ 根 ➜ 右即可,快速模仿并写出代码
1 | class Solution: |
同理在这里也附上使用helper()函数的标准写法,代码上来说,只变了名称和访问顺序
1 | def inorderTraversal1(self, root): |
迭代算法
核心思路依旧是利用栈维护节点的访问顺序:左 ➜ 根 ➜ 右。使用一个p_node来指向当前访问节点,p是代表指针point,另外有一个变量cur_node表示当前正在操作节点(把出栈节点值加入输出数组中),算法步骤如下(可以对照代码注释)
① 访问当前节点,如果当前节点有左孩子,则把它的左孩子都入栈,移动当前节点到左孩子,重复第一步直到当前节点没有左孩子
② 当当前节点没有左孩子时,栈顶节点出栈,加入结果数组
③ 当前节点指向栈顶节点的右节点
1 | class Solution: |
如果想要精简代码,从逻辑上来看,p_node可以使用root代替,这样写只是为了让代码更可读,和逻辑链相切合,方便理解
后续遍历
在线刷题:145. Binary Tree Postorder Traversal
递归算法
同理先序遍历,代码如下
1 | class Solution: |
节省版面,使用helper()函数的写法只需要改变函数名和访问顺序
迭代算法 1
后序遍历访问顺序要求为左 ➜ 右 ➜ 根,在对访问节点进行操作的条件是,它的左子树和右子树都已经被访问。这样算法的框架就出来了:只需要对每个节点进行标记,表示这个节点有没有被访问,一个节点能否进行操作的条件就是这个节点的左右节点都被访问过了。
因为栈先入后出,为了维护访问顺序满足条件,入栈顺序应该是根 ➜ 右 ➜ 左(和要求访问顺序相反)。代码如下
1 | class Solution: |
迭代算法 2
还有一种迭代算法利用后序遍历的本身属性,注意到后序遍历的顺序是左 ➜ 右 ➜ 根,那么反序的话,就直接倒序的输出结果,即反后序:根 ➜ 右 ➜ 左,和先序遍历的根 ➜ 左 ➜ 右对比,发现只需要稍微改一下代码就可以得到反后序的结果,参考先序遍历,代码如下
1 | class Solution: |
广度遍历
从上到下的层序102. Binary Tree Level Order Traversal
从下到上的层序(Bottom-up) 107. Binary Tree Level Order Traversal 2
按照层序进行遍历的的过程,有两种说法,一种是按照层序的从顶到底的(level order),另一种是从底到顶的(bottom up),具体实现上来说,就是输出反序即可。在具体问题设计上可能有区别,但是基本思路不变
广度遍历的核心思路就是使用队列,即先进先出 First-in First-out,这里很关键的一点就是以层来作为入队和出队的判断条件。并且因为按照层的顺序,是从左到右,所以遍历顺序(入队顺序)为左 ➜ 右
基本思路参看代码注释,逻辑比较简单。实现上,使用Python中的自带类deque来实现,新建为queue = deque([]),入队为queue.append(),出队为queue.popleft()
1 | from collections import deque |
Brew作者被拒的题
226. Invert Binary Tree,就是一道基本的树的遍历题。有故事说Mac包管理工具Brew的作者Max在Google被面试这道题,没写出来,被拒了。之后Max去了Apple。个人感觉,对于遍历的理解,如果是真的根据逻辑链理解,且对递归有着深刻的理解,那实在不应该写不出这道题,因为真的很简单
题目是这样说的,要求把一颗二叉树的所有左右子树互换位置
递归算法
假设左右子树都搞定了,那么当前节点需要的操作为:把当前节点的左右孩子互换即可,写成递归非常简洁
1 | class Solution: |
迭代算法
因为对于每一个节点,只需要把它的左右孩子互换位置,并且依次遍历即可,使用DFS或BFS都是一样的,这里用使用栈的深度优先搜索举例
1 | class Solution: |
总结
二叉树遍历问题最关键的逻辑链记忆点如下
遍历顺序
⭐️遍历顺序非常重要,即
某 ➜ 某 ➜ 某。如果这一点你不太记得,我认为在考试的过程中可以尝试向面试官确认,某的带选项只有三个,就是根,左,右,全排列也只有6种,长时间不用不记得也是情有可原的。所以在这里非常优秀递归 ➜ 假设搞定了
确认遍历顺序后,写出递归方法的核心思维是:⭐️假设左右孩子搞定了(搞定的方式就是调用函数本身,替换自变量即可),现在怎么做才能得到最终答案
- 迭代 ➜ 根的位置
一般面试官会继续询问迭代方法如何写,这里的核心思维是:⭐️关注根的位置,根对应的就是出栈输出的操作(在例题中就是添加到输出数组)
那么根据遍历顺序,⭐️只要根之前的左或右孩子不为空就不能出栈输出,要继续入栈(办法自己想即可,每次可能写出来的代码都不同,但是思路相同。需要例子,可以参考中序和后序里的迭代算法部分)

